I have a bit of a soft spot for legacy systems. They have a certain charming ugliness to them. Clearly, there is a ton of challenges with legacy projects, partly related to organizational incentives, and partly related to technical concerns.
Sometimes the response to these challenges is: Let’s rewrite all of it. I think that this is a very risky approach that can easily land the project in an in-between state which is worse than the place where it started from.

A pattern that can lead to this situation is the following: As an organization is incentivized to put as much weight as possible behind what is hoped to be the next cash cow, it attempts to run legacy projects with an as small as possible investment. This makes economic sense!
When problems pop up, investing in a legacy codebase is not a priority. Instead, issues are corrected with quick fixes and shortcuts. This constitutes a classic important-but-not-urgent issue. In the presence of other important and urgent problems, structural shortcomings in a legacy codebase won’t be tackled until they become urgent.
One day, the cries of distress from the people maintaining the system will become so loud that they can no longer be ignored and the decision is taken to take care of this problem once and for all! By that time, the system is in a bad state, so what can we do to solve the issue for good? The team, when asked, responds that only a total rewrite can save the day.
From the perspective of an engineer, a rewrite is tempting: It holds the promise of eliminating the technical debt heaped up over the years in one fell swoop. Furthermore, it also provides an exit to escape the career risks associated with the dead-end nature of legacy system maintenance. It is a way to not abandon the current responsibilities and benefit from the domain knowledge gathered over the years but still get a chance to dive into more recent technologies.
The management might find the alternative tempting as it promises to resolve the business risk associated with this project once and for all: One initial investment to eliminate all the recurring problems that the system has caused.
As tempting as it looks, I think that complete from-scratch rewrites of legacy systems are rarely a good approach: Usually, the siren’s call of a future free of maintenance is a mirage. Even if the rewrite is successful, there is no guarantee that the new system will be inherently more stable than the old one.
Even worse, complete from scratch rewrites risk ending up in an in-between state in which you have to maintain the new system but also cannot switch off the old one. A situation that is arguably worse than the situation you started from.
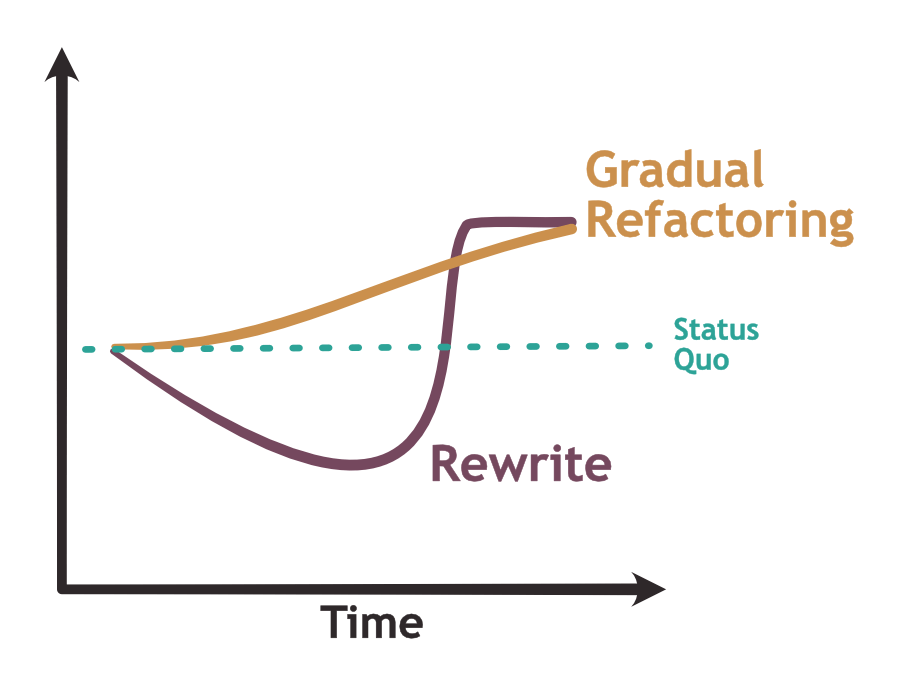
As long as the new system is not yet feature-complete, you cannot pull the plug on the old one. This means that until that moment when you can finally pull the plug, the new system will start to make things harder as you have more things to maintain at the same time.
In the worst-case scenario, some users or processes will have adopted the new system while others still rely on the old one at a moment of organizational turmoil. Management might decide to pull the plug leaving you with an even more complicated maintenance problem than the one that you started with.
I do want to point out that – as always – there are exceptions. If a system’s functionality is almost completely subsumed by existing off-the-shelf components, it may be worth switching over to that component. If, for example, your system is basically a re-implementation of a relational database, maybe it is indeed a good idea to switch that out for a PostgresSQL for example. Note, that here the big challenge will be migrating all the systems that still interact with the legacy system in some way and that the same risks still apply. This will require careful analysis.

Leave a comment