Cutting up large systems into smaller components is one typical task of software architecture. Many modern architectures follow a (micro-) service pattern which is one particular family of strategies to decompose a larger system into smaller parts. It would be short-sighted to apply any such method without consideration of its respective strengths and weaknesses and without a thorough examination of the rest of the design space.
In particular, it appears to me that decomposing a system serves multiple different functions. The most appropriate place to apply the scissors depends on the circumstances. Instead of blindly following a paradigm like micro-services, let us instead try to identify the different dimensions along which cuts can be placed, what their interactions are, and what alternative strategies exist.

Imagine your overall system as a plane on which each point is a line of code or a piece of functionality. A lot of software architecture consists in drawing lines on this plane so that some parts of your system are in one box and other parts are in another. In this article, I would like to propose a framework for thinking about system decomposition which suggests that such cuts can be made in five different dimensions.
Take the simple example of deciding how to manage your code repositories. Does all your code live in one big repository or do you make one or several cuts, spreading the code into multiple repositories? As a result of this decision, each point of the plane that is your system has been associated with exactly one repository, giving you one possible partitioning of the system.
Cuts in each of the dimensions interact with the other four dimensions. However, that does not mean that the cuts all need to be at the same places.
Here are the five cutting dimensions that I want to consider in this article. Below we will talk in more detail about each one of them and their interactions:
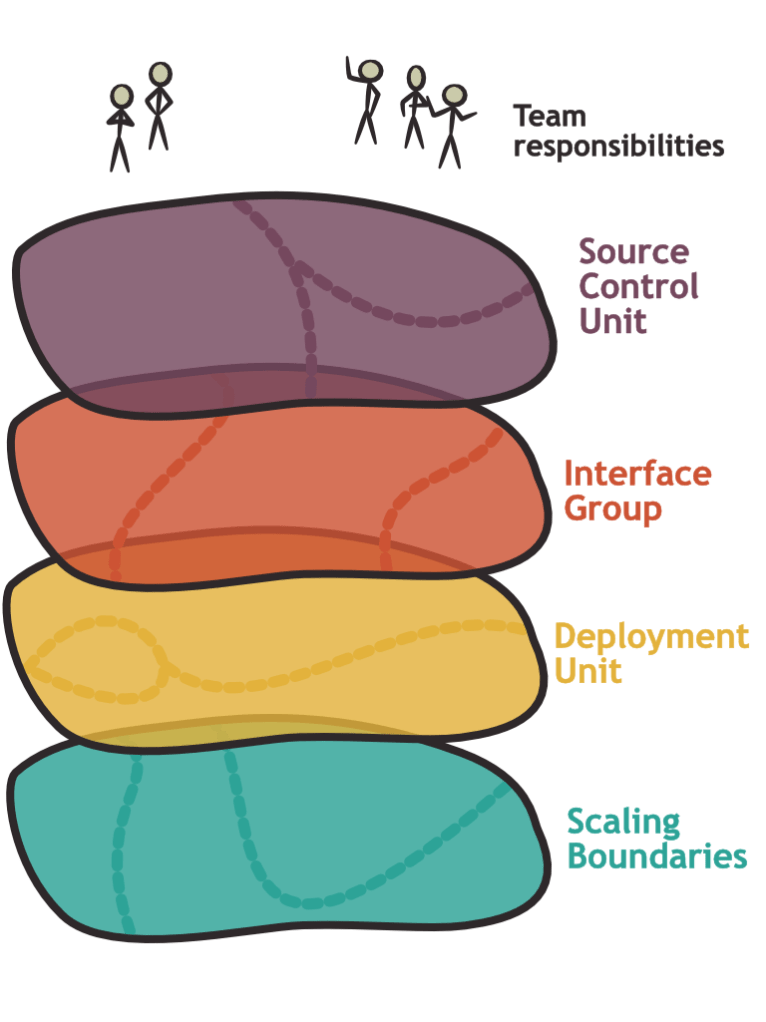
Team responsibilities are the place where the organization makes cuts: For each line of code, each point on the plane, we need to state which team is responsible. Multiple teams can in theory be responsible for the same line of code, which sometimes happens when ownership is transferred or when shared components are created.
Source control units are the cuts that we already talked about: How do you physically separate your code into repositories?
Interface groups are the lines that bundle together units of functionality. A library or an API could form such a unit. We often choose these lines as a result of the domain model or around functions that manipulate the same state.
Deployment units are buckets of functionality that are deployed together. In other words, two lines of code that are in different deployment units should be deployable independently.
Scaling boundaries are pieces of infrastructure that can be scaled independently: If you have a bottleneck located in one particular part of your code base and you decide to increase capacity, which other lines of code will benefit from the same increase? For example, in a typical service architecture, one service is a scaling unit. You can add more instances of the service for horizontal scaling which will scale up all the API endpoints offered by this service.
Let us consider these dimensions one by one in more depth to see, how they interact with other dimensions and what some of the considerations are when cutting the system in this dimension.
Scaling Boundaries
The bottom layer of the hierarchy is the rather technical question of how you can allocate computation resources across the points that make up the overall system. This does not need to mean horizontal scaling: You may want to make a more powerful GPU available to certain parts of the system. The question remains: How narrowly can you pinpoint one part of the system that benefits from the additional resources?
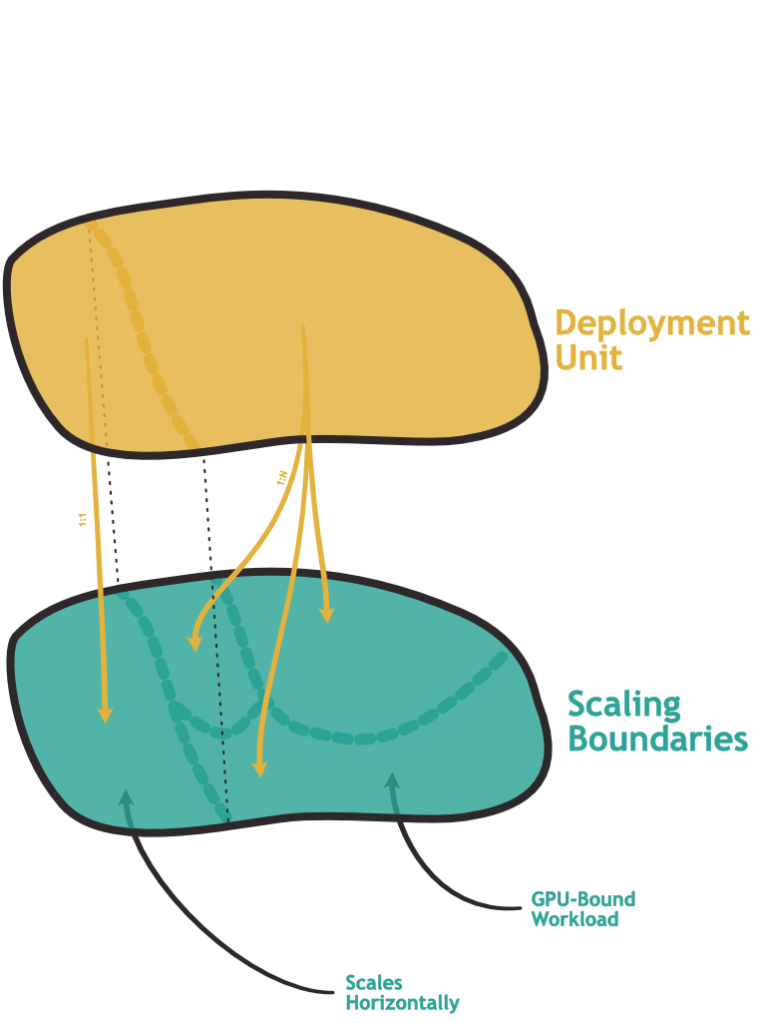
A monolithic application would typically be all or nothing: Either the entire application runs on expensive hardware or none of it does.
It is common for services to form independent scaling units. When we look at the interaction with deployment units, there seems to be a correlation: Infrastructure that can get deployed independently often can be brought to scale independently.
What about the other direction? Can we make the cuts in the scaling dimension more granular than deployment units or interface groups? It turns out that we can: We could, for example, deploy a service to AWS using an API Gateway backed by individual Lambda instances. While the deployment is one unit, forming one consistent functional API, each of the lambdas can scale independently.
Granularly scaling your system can be a good thing to make efficient use of computational resources and to quickly react to changed load. Not every system will have this problem, though: Some may experience uniform loads with similar computational requirements in each part of the system, making independent scaling less interesting. Some may have such a small computational footprint that the additional effort is just not worth it.
A second important function of the boundaries is to avoid propagation of failure: If one part of the system exhausts a resource because of a bug or exceptional load, will this bring down another part of the system? Deploying different parts of the system onto different machines reduces the risk of failures spreading through the entire system. (This could potentially be seen as an entirely separate dimension as there is more to the story of failure isolation.)
What are the downsides of increasing the granularity in this dimension? I think the biggest challenge with drawing a new scaling boundary is that it changes how the two sides of the system communicate with each other. If two points on your system plane live on the same physical hardware, they typically have access to shared memory and other very reliable communication methods. When you cut up your system so that it can run on different machines, you will have to depend on messages sent over an unreliable network with all the challenges that come with distributed systems.
An important corollary is, that it is easy to draw a scaling boundary between two parts of the system that are not tightly coupled, and that require no or very little exchange of information with each other. This is one of the reasons why it sometimes makes sense to consider interface groups as the most logical place to make these cuts as they are the primary place where we think about the communication patterns between subsystems.
It is important to note that the considerations in this dimension are purely technical and based on an analysis of what load your system is likely to experience.
Deployment Units
This leads us to the next level: How do you decide which parts of a system you deploy together?
The “mythical monolith” would typically form one deployment unit. Would it be possible to use deployment units that are smaller than one interface group? I think that technically, this could potentially be achieved. Nevertheless, it is often not very interesting for the following reasons: Firstly, the interface forms a coherent entity to the outside, the customer, or the user of this subsystem. Deployments signify change. Usually, we want one functional unit of the system to change in one coherent step and not in many small uncorrelated increments of individual functions. Secondly, an interface is often formed around a shared state which makes it necessary to synchronize changes – especially those that concern the data model.
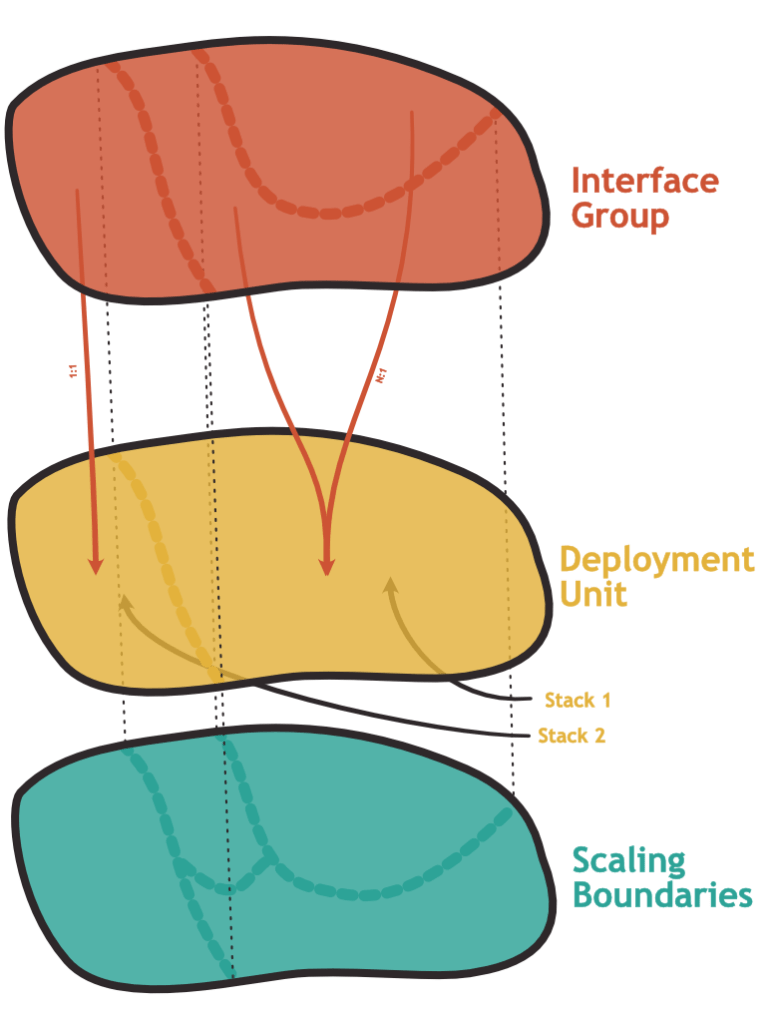
What about making deployment units larger than interface groups? Is that possible and if yes, should we do it?
We can certainly bundle multiple components together into one package that is then deployed in one go. If one of the components receives an update, we update the bundle and deploy a new version. We could even define a cloudformation/terraform package which describes our entire system.
This approach is not very fashionable at the moment but it has some advantages: You always know exactly which combination of artifact versions has been deployed at any given point in time. When you have a multi-stage deployment process, you can make sure to not only test each component individually exhaustively before promoting it to the next stage. You can also make sure that the entire system with exactly that combination of versions has run on one stage before passing it to the next. The package that bundles the entire system together can also perform compatibility checks to rule out deployments of versions that are known to not work together. Deploying the entire system together gives you more flexibility in specifying dependencies between components, making it easier to perform migrations that touch multiple parts of the system: You can cut down on temporary deprecation and compatibility code as you can control in which order each component will be deployed. Finally, having one bundle that represents the entire system makes it easier to go and deploy the entire system to a new environment – for example for testing.
One of the reasons this is not fashionable is that it might make the coupling between components just a bit too easy. You might end up with the dreaded distributed monolith. Another reason is the interaction with the team responsibility dimension: If multiple teams are working on the system, we have just introduced a shared component which might can cause coordination overhead. Finally, cutting up the deployment leaves more flexibility in deciding how and where to deploy each of the components.
Certainly, you can take the monolithic deployment philosophy too far. Imagine all the code of a large organization being deployed through a single deployment pipeline that collects all changes into a central system artifact. This would be a mess: If the system applies each change separately, your changes will end up in a long queue, waiting for their turn to be deployed. To avoid that, the system would have to batch changes together. However, the implication of this is that rollbacks would undo completely unrelated changes just because they happened to be batched into the same deployment creating an unnecessary coupling between teams.
If more than a handful of teams share the same monolithic deployment unit, you would have to come up with tooling or strategies to resolve such dependencies.
With these trade-offs in mind, I think that we can conclude that the interactions with the team dimension will be the decisive element when deciding on the best cuts in the deployment dimension.
Interface Groups
We already noticed that the bundling of code in functional packages typically occurs along domain considerations (e.g. the service that handles payments) or shared state (e.g. a service that manages customer information). When I talk about interfaces, I don’t necessarily talk about web APIs. There could be a piece of code in your solution that solves linear optimization problems which is distributed as a library. There could be an analytics job that in regular intervals read Excel files from a Dropbox folder – in this case, the file exchange is the interface and the code doing the analytics is the subset of the system forming one interface group. Sometimes services access the same database (an anti-pattern according to the microservices philosophy) which makes the DB a part of the interface between these two services.
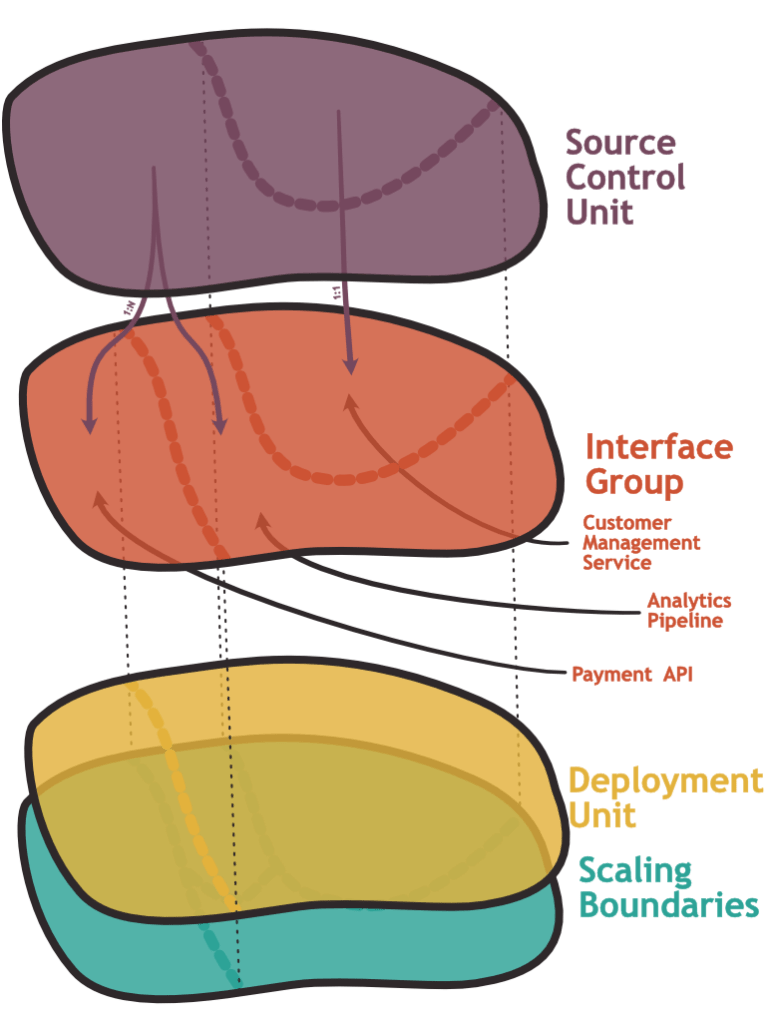
Next to domain and state, there are other considerations to take into account: For one, does the grouping make sense for the user of the interface? There is a user experience aspect to this decision. A god-service that handles payments, your shopping list, and analytics might not result in the experience that you aimed for.
There is also a link to team responsibilities: If you want to keep an interface of one such interface group consistent and maintained, it is probably a good idea to not have more than one team responsible for the same interface group.
Source Control Units
We are now more and more moving from technical partitioning to human-centric partitioning of the system. One important question to ask is where the code lives physically. In today’s software development practice this almost always means a repository of a version control system like git or mercurial.
There are many ways in which these systems can be used and as before, the way in which you distribute your code over version control repositories interacts with the other dimensions of the hierarchy.
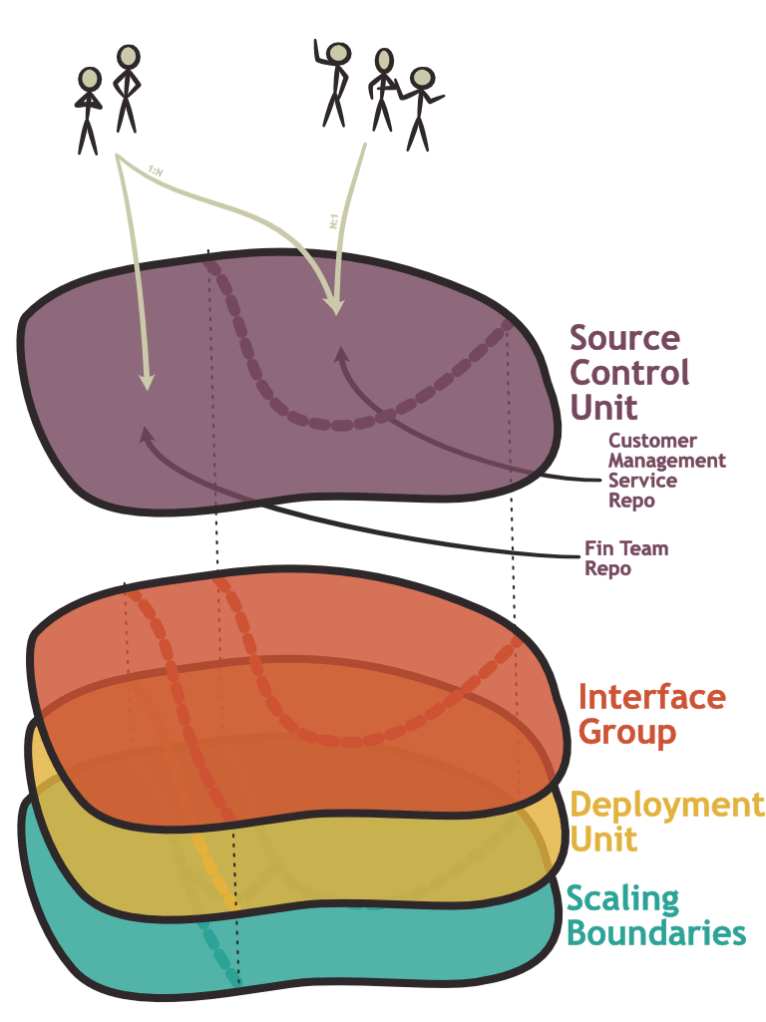
Let us first consider, how the source control partitioning interacts with the interface group layer. Could one interface group be partitioned over several repositories? This seems possible. For example, you could have a repository for your service, and a separate repository for config files associated with your service. In practice, this is not often done in my experience. The reason for this is that code in the same interface group often changes together. A change in the service code might require a corresponding change in the configuration. Usually, spreading a change over multiple repositories comes with additional overhead, unless there is special tooling involved to make this easier.
Conversely, multiple interface groups can be managed in the same source control repository. In the most extreme case, your entire system is stored in the same monorepo.
This would make it easier to synchronize changes that affect multiple components and larger automated refactoring like introducing consistent formatting become easier to execute. You also have one source control revision which represents a version of the entire system which can have certain advantages, especially when combined with a monolithic deployment unit.
Of course, this comes with downsides. One problem is that for many teams, one repository is the unit that a CI system operates on. If one repository is very large, additional tooling may be required to only build and test parts of the system that changed to avoid prohibitively long build times.
The more serious challenges are in the mapping of teams to repositories: In theory, one team can be responsible for multiple repositories and the same repository can be worked on by several teams. In my experience, it helps to have clear ownership: If there is a problem in one piece of code, it should be clear which team is responsible for fixing it. In the extreme case of a monorepo worked on by several teams, you could define responsibilities based on a criterion other than the repository but extra care needs to be taken that the changes that team A makes do not slow down the work of team B.
Similarly, if one team needs to maintain many different repositories, extra care needs to be taken that none of these repositories get neglected.
Note, that “Source Control Unit” does not need to map to “repository”: Famously, Google stores its entire code base in one big monorepo. In such a system, you will have to create additional tooling to subdivide the repository on a folder level. I would argue, that in such a setup you could just consider these folders as the Source Control Units. Conversely, you could probably come up with tooling that allows groupings of very granular source control repositories into one unit. In this case, I would consider such a grouping as a unit in the sense of this article. At the end of the day you need to put your code somewhere and tell your teams which of these locations they are responsible for – this forms a natural partitioning.
Team Responsibilities
Team responsibilities is an important dimension of decomposition which interacts with each of the other dimensions. This is not really for technical reasons: As we have seen, multiple teams can technically own a shared repository, a shared interface group or different parts of the same deployment unit. It is just as possible that one and the same team owns many different services.
In practice, however, it has been observed that there are strong forces that favor an alignment of the system decomposition with the way that teams are structured. This is known as Conway‘s law.
In my experience, Conway’s law has its roots in communication patterns. A small enough team (let’s say up to 8-10 people for the sake of being concrete) can communicate efficiently through informal channels. I can quickly ask a coworker if they are going to push any conflicting changes. I can get an explanation about a piece of code. The team can quickly align on shared coding standards and architectures. The team can thus share responsibility for activities that require a high degree of coordination.
Once you go beyond this team size, coordination effort becomes more painful. More different voices and incentives are involved. Getting everyone around the same table is difficult and costly.
As a consequence, you will face friction if the other dimensions of your system are cut in such a way that different teams need to coordinate their work. This happens if two teams work on the same API, operate on code in the same physical location or depend on each other during deployment.
Note furthermore the following corollary: If the entire system is small enough to fit into the responsibility of one developer team, many of these other decisions become much less critical.
What does that mean in practice? We have already seen, that the same team can own multiple repositories. This can come with additional overhead, unless there is tooling in place to overcome this overhead. Multiple teams can also share the same repository which can introduce coordination overhead as described above – unless tooling is introduced to resolve this friction.
Similarly, imagine multiple teams owning different parts of an interface group. The goal of an interface group is to be intrinsically consistent. By definition, any team making changes would need to coordinate with the other team, introducing friction.
Micro-Services Revisited
With this framework in mind, let us consider the cuts that a team following a typical micro-services pattern is making. Micro-services do not prescribe particular cuts in all of these dimensions – but the philosophy favors a separation that looks a bit like the following picture:

One service is used as the partitioning unit and this partitioning then extends into all of the dimensions. Each service scales independently, gets deployed independently, and lives within its own repository. Each team can maintain several such services.
I don’t think the pattern is necessarily bad. There are some practical concerns that I have about the difficulty of keeping services truly decoupled long-term but that’s a topic for another time.
There are some positive things to say about cutting all dimensions at the same place: One aspect is that it is simple. The other benefit is that a cut that separates the system in several dimensions is often a natural choice: As we have seen, it is necessary to consider communication patterns (interface groups) when deciding how to distribute the system onto different pieces of hardware (scaling boundaries). Similarly, we have seen that it can make sense to not have many teams share the same deployment unit to avoid coordination overhead.
The biggest issue that I want to highlight is that we risk mixing up different motivations when choosing this setup. For example: Are we mainly interested in scalability and we can expect not more than one or two teams maintaining the system? Then we could likely simplify our lives by removing cuts in several dimensions.
Furthermore, I find the name itself problematic: The word “micro” suggests that the main factor that should determine the subsystem boundaries is the size of these subsystems. A lot of small cuts would appear to have intrinsic value. This looks like an anti-pattern that detracts from the underlying goal of finding the strategically best-place cuts in the system architecture to meet the scaling- and operational targets of the system that are at the same time consistent with the team topologies.
About Change
One of the problems that I ignored above is that system cuts tend to be more permanent than the organizational environment. We have seen that team responsibilities are one of the main factors that determine the quality of a cut. You might find yourself in a situation where you finish the cut right in time for another swing of the reorganization pendulum.
This is an argument in favor of very granular decomposition, even if it comes with significant overhead: Having many very fine-grained components makes it easier to map a new organizational structure to a changed grouping of these granular components.
One of the obvious places where this can be observed is the source control units: In a static environment, it might make sense to have one repository per team, even if that team is working on different functional components. This works but can become a problem after the next reorg when suddenly several teams find themselves responsible for code in the same repository. Disentangling this comes with additional work which was probably not accounted for by whoever organized the reorg.
Conclusion
In the end, I just want to encourage everyone working on software architecture to go through the following exercise the next time that you have to make cuts in a system: Consider each dimension one by one and ask yourself what a very granular or very coarse partitioning would look like. Do you need to scale parts of the system separately? If yes, are these the same parts that also form distinct deployment units? What would happen if you deployed everything together? Do you need to create two separate APIs or interfaces, just because you want independent deployments? What would happen if all the code moved into one repository?
At the end of the day, you want two things: You want to satisfy the operational constraints of the system and you want efficient progress when making changes in the future. The latter aspect requires that teams can do their work without stepping onto each other’s feet but also development practices that are light on overhead.
The exact dimensions in your project might differ from those presented here but I think that we should step away from a “package deal” that are micro services and do our own analysis instead.

Leave a comment