When designing distributed systems, we sometimes think of latency and availability as two technical dimensions to balance out in our designs. I would like to argue that a more useful perspective would be to see them as two sides of the same coin.

When discussing the design of a system, we typically need to carefully examine the constraints that the system has to work with. So-called non-functional requirements guide the engineering team to the appropriate area of the solution space. In this context, you might say or hear things like: “Availability is a more important concern than latency” or “latency does not matter for this use case”. Conversely, you might be faced with an extremely time-critical system where latency is so important that after a while it does not matter whether or not the system responds at all (videoconferencing, gaming or any system with real-time constraints come to mind).
Some design decisions tend to be presented as a latency-availability trade-off. Take the example of synchronous versus asynchronous processing of a request. In synchronous processing, a client calls a service and keeps the connection open waiting for a response. That service might in turn call other services, following the same mechanism.
Take the following example of an application serving travel recommendations which in turn calls a weather service to get location-specific weather information:
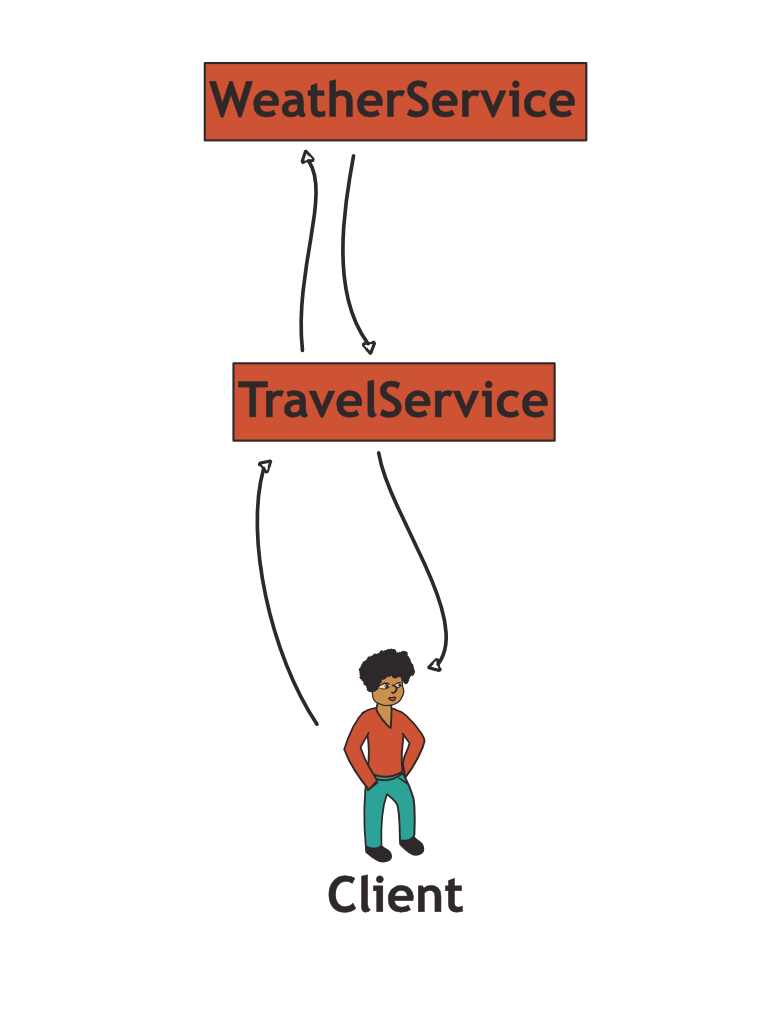
Imagine what happens if the weather service is not responding or if network connectivity between the two backend systems drops:
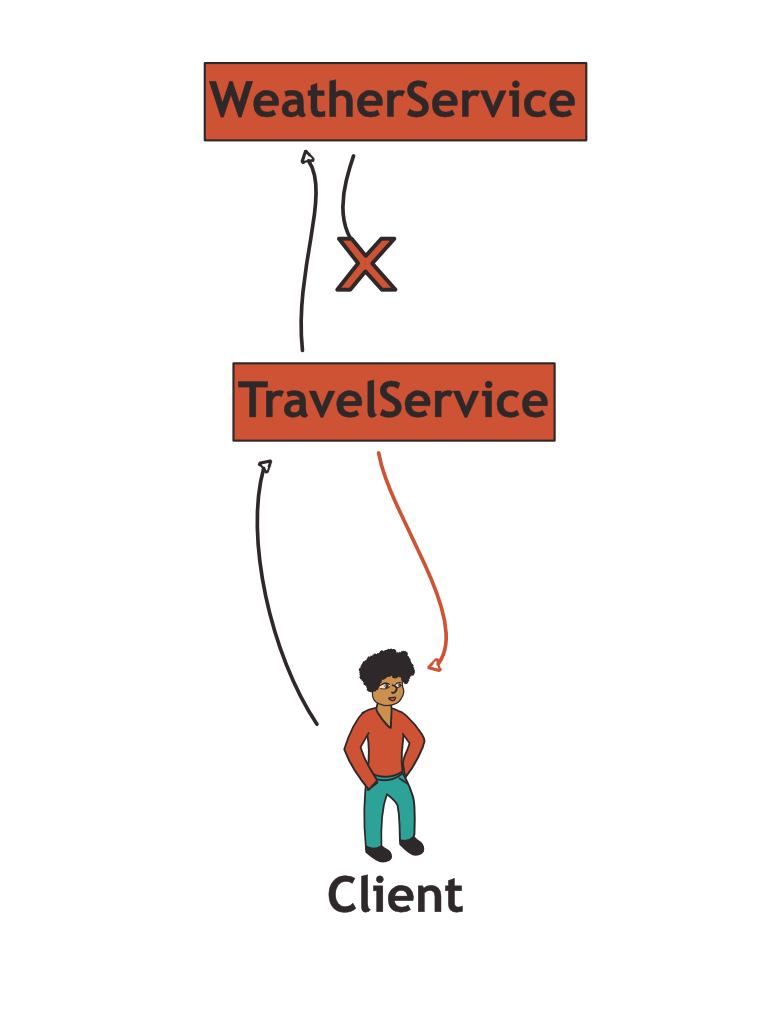
In a synchronous call, the service would respond with a failure, effectively compromising availability. This is one of the typical challenges of distributed systems: The availability of a system A that depends on a system B is constrained by the availability of system B
The same system could be re-architected as an asynchronous process. Here, the general idea is that messages get passed through the system through a sequence of persisted queues. (Strictly speaking, the request in the inbox of a service in the synchronous model will probably also land in some kind of queue – but those are not persisted in a failure scenario). Every component in the system consumes messages from a queue and writes its results back to a different queue. One possible asynchronous formulation of the system above looks as follows:
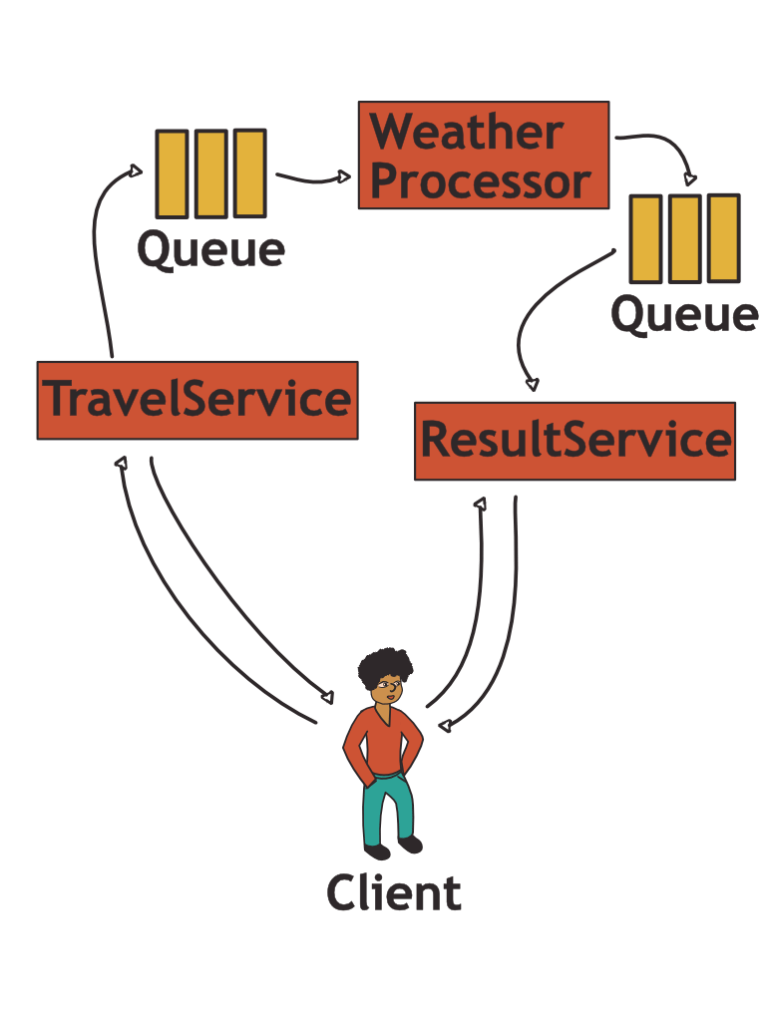
If the weather processor experiences an outage, the message would wait in the queue until the temporary situation is resolved. While the system was available to the client, the latency increased.
Two sides of the same coin
Now that I have built up a formidable strawman, let me try to tear it back down: Are availability and latency different dimensions in practice? I would argue that they are very similar: There is likely always a latency threshold after which the client would consider the system effectively unavailable. For example, what if you have to wait for 5 seconds, 15 seconds, or even 30 minutes for your response? Conversely, let us consider what the client will do if it receives an “unavailable” response from the service: Very likely it will retry the call. This can happen either automatically over a certain period, or manually because the user triggers the same action again. Assuming that one of the retries succeeds eventually, from the user’s perspective, the client has thus transformed the availability problem into a latency problem.
In that sense, it would appear that latency is all that really matters: What counts is the time between the user intent (“give me my travel advice”) and the moment where the requested information is received. Whether the system returns occasional status updates saying “not possible at this moment, please try again” or whether it simply waits until the response is ready is more of an implementation detail.
We can also note, that semantically, the main difference between the synchronous and the asynchronous formulation of our system is the fact that in each synchronous call we determine a timeout value after which the connection is considered lost. These timeouts are effectively the cut-off points where we decide to bubble the problem back up to the caller. One challenge with synchronous systems is that often, we do not have a good sense which cut-off values would be appropriate.
What to Measure
From this perspective, I would argue that when talking about system reliability, there should be better metrics than the traditional number of nines that a system guarantees. What we should provide is guarantees about the distribution of responsiveness which should be measured as the time between the first client attempt and the effective delivery of the information. For example, we could make statements about the different percentiles of this distribution to define an SLA.
Measuring availability in terms of failures to respond to individual requests is at best a crutch to help with an unfortunate visibility issue: It is hard to establish that two client requests express the same intent. There are ways to try and get this data: For example, we could ask clients to include request IDs that remain equal as long as they represent the same intent. Though, I suspect that these attempts will again come with tricky edge cases.
Note that the asynchronous formulation mitigates this visibility problem somewhat but does not completely solve it: We also need to consider the possibility that the entry point where the client first places a request becomes unavailable. The asynchronous formulation also introduces the opposite visibility problem: Even though we can more reliably measure the end-to-end response time, we loose the information about the duration after which the client gives up and stops being interested in the result.
With all of that said, it’s a useful realization for system design that we can focus on one dimension rather than having to balance out two: The distribution of end-to-end response times. Whether it is okay to respond a 503 error code for temporary unavailability mainly depends on whether the client can tolerate another network round trip.

Leave a comment