In this article, I want to explore a strategy of dependency management that enables transitive dependencies to evolve independently and to disentangle the gnarly problem of conflicting transitive dependencies.

Dependency hell is a real place. The times I am struggling trying to find a matching set of dependencies are moments in which I ask myself whether we have really made progress as a field or if we are just solving the same problems as our programming forefathers and the principal change is that we’ve now got emojis in our terminal output.
One of the consequences of dependency hell is that updating dependency versions can become so painful that teams avoid doing it. This in turn can lead to missed critical security patches and Big Bang updates.
In the following, I want to present a thought experiment to try to turn dependency management inside-out. I’m not sure how practical the strategy really is. This article will highlight some of the challenges. I do think that with a lot of effort, this could be back-fitted on existing programming languages and build tools but more exploration would be necessary.
With that out of the way, let us consider the biggest contributor to dependency hell: The diamond dependency problem.
The diamond dependency problem arises when two of your dependencies depend on different versions of the same artifact.
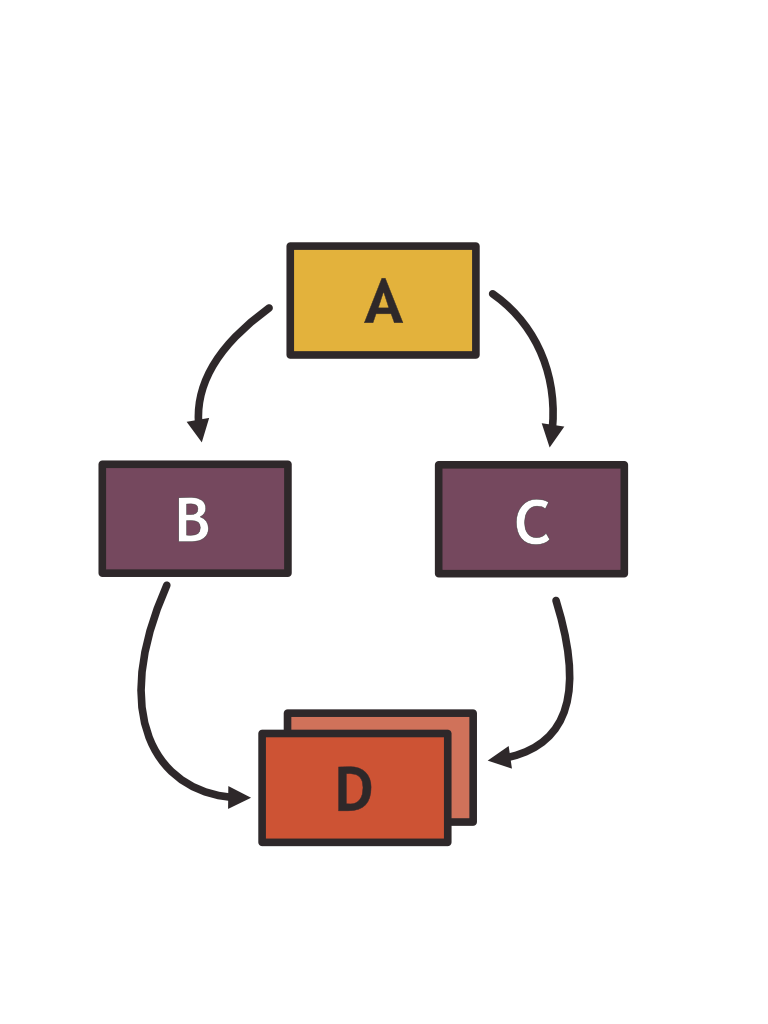
To see why this is problematic, consider how most build systems resolve dependencies. In most systems, every artifact defines a range of upstream package versions that it is compatible with. Often, we make use of semantic versioning for this purpose: You could consider that a patch version update will not break compatibility and allow all patch versions of a given minor version. Or you could define a fixed range that you tested your artifact against.
Whatever it may be, when artifact A pulls in D which is a transitive dependency of B and C as shown in the image above, two things can happen:
- It may occur that the version ranges that B and C define do not overlap. This means that the system is not able to find a set of versions that satisfy the constraints. You will need to start playing with the versions of B and C to find a combination that works. Finding a set of versions that satisfy all version constraints is famously NP-hard and a source of complexity in modern build systems.
- The second thing that can happen is that the system resolves D to a version that is in the range but that neither B nor C has been built and tested against. This could lead to code breaking in subtle ways at runtime: The author of C might have been too optimistic in their version bounds and all of a sudden, some behavior change in D changes the behavior of C.
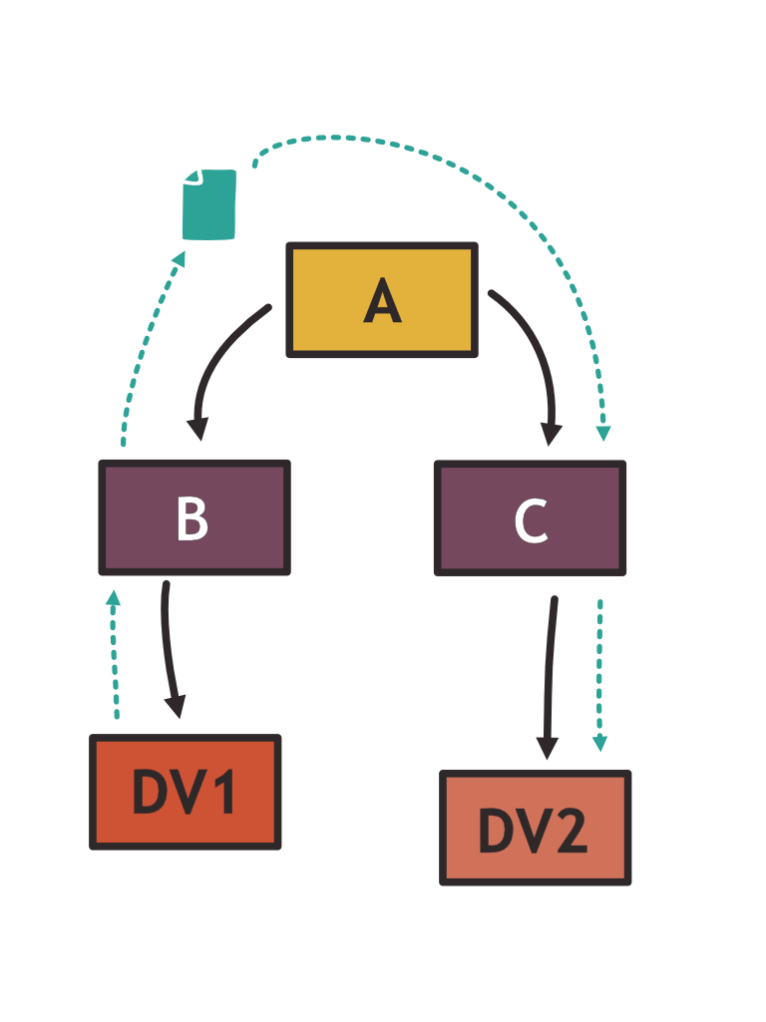
A first observation to approach a solution is the following: Note how we can get around both problems by treating each version of D as a new package: DV1, DV2, etc. This is a bit like statically baking the dependency at compile time (but not quite as we will see later).
The result is that B and C each depend on their own version of D and can get pulled into A without conflict.
What if the code in A wants to access a type or function of D? To make sure that A can use D transitively, we need to make sure the module names associated with different versions of D are different. The author of A can thus decide which version of D to use by specifying the version in the import. Again, this works because now for all practical purposes, DV1 and DV2 are two completely separate packages.
Of course, the solution is not going to be that easy: Now we have a problem if A wants to combine both versions. This could happen if A passes data produced by DV1 through B to a function in A that passes the data down to DV2. In other words, treating DV1 and DV2 as completely separate packages breaks down when we want to use the fact that they are to a large extent the same library.
Let’s look at a (somewhat contrived) example to make this more concrete. Consider the following setup: We have a package called UserDefinitions which contains (among other things) a class representing a user. We furthermore have a package called UserProducer which creates new users and a package called UserConsumer which requires user data to function.
Here are two successive versions of our UserDefinitions package (written in pseudo-Java and assuming that the compiler will do what we would expect):
// Version 1
package example.user_definitions.v1
class User {
public String name;
}
// Version 2
package example.user_definitions.v2
class User {
public String name;
public int age;
}
The UserProducer in this example has updated to version two of the UserDefinitions package and exports the following module:
package example.user_producer.v1
import example.user_definitions.v2.User;
class UserProducer{
public static User produceUser() {
return new User("SomeName", 45);
}
}
The UserConsumer package on the other hand still relies on version one of UserDefinitions and is defined as follows:
package example.user_consumer.v1
import example.user_definitions.v1.User;
class UserConsumer{
public static void consumeUser(User user) {
print(user.name);
}
}
Now, in our Application module, we want to somehow make these dependencies work together by providing a user object that was produced by the UserProducer as input to the UserConsumer. However, because of the conflicting versions and because the two versions of UserDefinitions now are treated as completely separate packages, this will not work:
package example.application.v1
import example.user_producer.v1.UserProducer;
import example.user_consumer.v1.UserConsumer;
import example.user_definitions.v2.User; // Here we have to decide...
class Application {
public static void main() {
User user = UserProducer.produceUser();
UserConsumer.consumeUser(user); // Oops, type error
}
}
Note that in this particular scenario, the change in User could be made backward compatible: A function that expects a v1. User should still be able to work with a v2.User object. In fact, we could modify our Application code to make this example work:
package example.application.v1
import example.user_producer.v1.UserProducer;
import example.user_consumer.v1.UserConsumer;
import example.user_definitions.v2.User as v2.User;
import example.user_definitions.v1.User as v1.User;
class Application {
public static void main() {
v2.User user = UserProducer.produceUser();
v1.User compatibilityUser = v1.User(user.name);
UserConsumer.consumeUser(compatibilityUser ); // Now this works
}
}
There are other possible scenarios. Another possible scenario is that the change from v1.User to v2.User is indeed completely incompatible and there is no way of supporting data from UserProducer in UserConsumer. In this case, the type system will block the author of the Application module from doing anything potentially dangerous.
While the solution presented so far is still clearly lacking when it comes to compatible changes, I would argue that for those changes that are actually incompatible, this is already an improvement: We can note that the author of Application only has a problem if they actually use the conflicting functionality. The author of the Application module could furthermore have specific domain knowledge about how user definitions will be used, allowing them to provide their own compatibility code even if no generic compatibility code can be provided. If that is not possible, they could try to work around the functions that cause the conflict. They have more options than before when the build already failed during dependency resolution.
Nevertheless, the more interesting question is what would happen if changes do indeed support some form of backward- or forward compatibility. In the example above, we saw that the author of package A could resolve the conflict. I would instead propose a strategy that pushes the responsibility for this task down to D.
The general intuition is that by making a version explicit, each library can depend on a previous version of itself. Here is an evolution of this example in which D makes sure that the data produced by a new version is compatible with functions that depend on a previous version:
// Version 1
package example.user_definitions.v1
class User {
public String name;
}
// Version 2
package example.user_definitions.v2
import export.user_definitions.v1.User;
class User extends v1.User {
public int age;
}
This is still not very convenient. The author of UserDefinitions no longer provides the full definition of the User object but only the delta with the previous version which is extremely awkward. However, assuming that the compiler and type checker does the right thing with these pseudo-Java definitions, this will resolve our problem: The original Application code we wanted to write now compiles. The author of the transitive dependency provided the necessary compatibility code and proved through the type system that it is indeed safe to use a v2.User instance in places where a v1.User instance is expected.
Let us look at compatibility in more detail: Note that there are two different kinds of objects that the transitive dependency could expose for which we need to guarantee compatibility. There is data (like the user definition provided above) and there are functions that take some data defined in by the same module as an argument. To achieve full compatibility, we want to cover both directions: Functions from a new version of the dependency should accept data from an old version. Conversely, functions from an old version should accept data from a new version. Note how this mirrors the definitions of forward- and backward compatibility of serialized data:
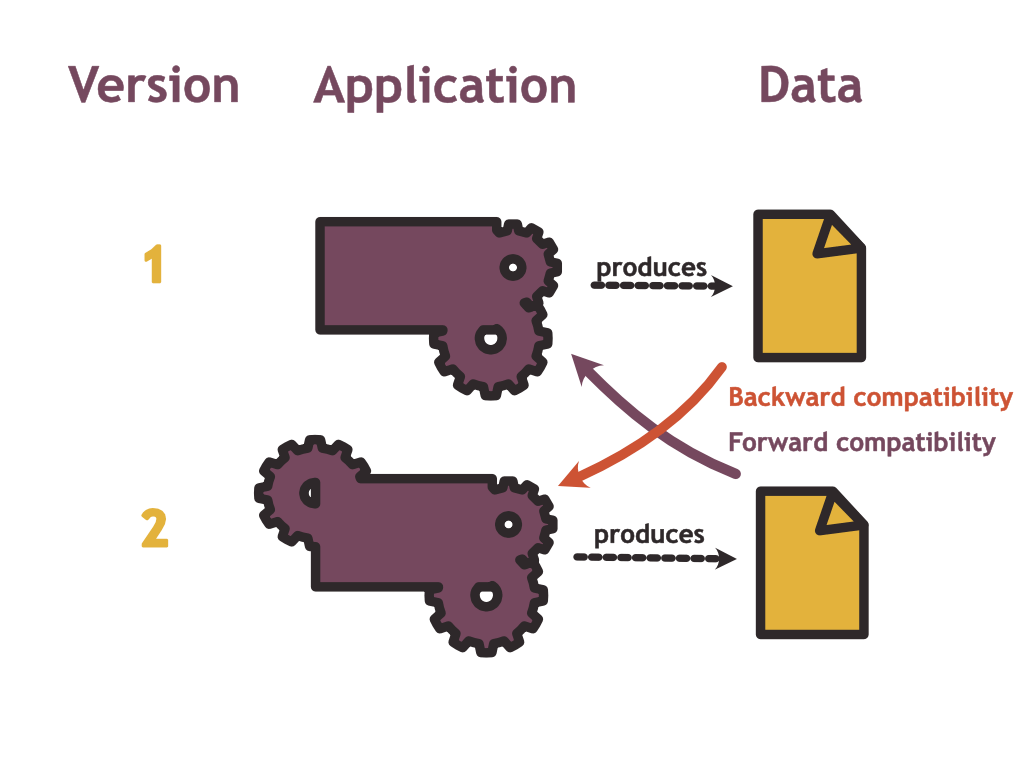
In the case of versioned artifacts I don’t consider it particularly useful to speak about forward compatibility for the following reason: The caller could obtain anything from the transitive dependency. This could be a piece of data or a function reference. Saying a function reference obtained from an old version should be compatible with data from a newer version of the same artifact feels like a backward compatibility problem. The difference with the serialization use case is that we typically serialize data and never serialize functions.
Backward Compatible Data
Following the discussion above, we want that data produced by a new version of a piece of code can be used by a function from an old version of the same code. The author of the user_definitions modules is responsible for providing compatibility if possible. We have already seen, how this could work in a simple example above. Now let us consider what would happen if the module has other functions in its external interface that we want to keep backward compatible:
// Version 1
package example.user_definitions.v1
class User {
public String name;
}
class UserWriter {
public void writeUser(User user) {
print(user.name);
}
}
// Version 2
package example.user_definitions.v2
import export.user_definitions.v1.User;
import export.user_definitions.v1.UserWriter;
class User extends v1.User {
public int age;
}
class UserWriter {
public void writeUser(v2.User user) {
print(user.name);
print(user.age);
}
}
This satisfies backward compatibility as an instance of the v2.User object can still be used by the v1.UserWriter.
Backward Compatible Functions
Now let us look at the flip side: Can data produced by an old version still be read by new versions of the same code? Consider the following adaptation of the example above:
// Version 1
package example.user_definitions.v1
class User {
public String name;
}
class UserWriter {
public void writeUser(User user) {
print(user.name);
}
}
// Version 2
package example.user_definitions.v2
import export.user_definitions.v1.User;
import export.user_definitions.v1.UserWriter;
class User extends v1.User {
public int age;
}
class UserWriter extends v1.UserWriter {
public void writeUser(v2.User user) {
print(user.name);
print(user.age);
}
}
We have now made this example forward-compatible: A v1.User instance can still be used with a v2.UserWriter.
Is It Reasonable To Require The Library Author To Manage Compatibility?
Let us now turn to some practical considerations.
First and foremost, the approach described here seems burdensome for the library author. In fact, treating every single release as a completely new artifact sounds crazy if we want to release multiple times per day. We would not want to write compatibility code for all objects in the entire library for every single such release! Furthermore, the practice of inheriting code from previous releases and only specifying the difference seems extremely unintuitive.
If we cannot make this convenient for library authors, it is a non-starter.
I think that there are ways to make this manageable using two ingredients. One is a language feature or tooling extension which does not look unreasonable. The other is a strategy of organizing the code.
The language feature that I think would be useful in this context is module aliases as a way of abstracting over modules or packages. I would like to express that a.b.c and x.y.z actually refer to the same package. So passing an instance of a.b.c.Foo to a method that expects a x.y.z.Foo should be absolutely fine. This could be managed by the build system as a form of “symlink” that is generated for such aliases. (How difficult it would be to backfit this onto existing language build tooling is a different question).
What this would allow us to do is to define in the build definition, that my.package.current is actually an alias for my.package.v3 and that my.package.previous is the same as my.package.v2. This in turn means that for the parts of my code that are not changing, nothing needs to be updated:
// ...
// Version 2
package example.user_definitions.current
import example.user_definitions.last.User;
import example.user_definitions.last.UserWriter;
interface User extends api.last.User {
}
interface UserWriter extends api.last.UserWriter {
}
Of course, we would need a mechanism to decide which of these aliases can be exported to the user of the library. If we would export the “current” and “previous” alias, we would end up in the same situation as before as there would be two packages that export conflicting module definitions.
The second ingredient that I think would make this manageable is to systematically separate interface and implementation. The type that is exposed to the user of the library should in general be an interface or a trait. This enables the following uses:
// Version 1
package example.user_definitions.api.current
interface User {
String name();
}
interface UserWriter {
void writeUser(User user);
}
package example.user_definitions.impl.current
import example_user_definitions.api.current.User;
import example_user_definitions.api.current.UserWriter;
class User implements api.current.User {
public String name;
}
class UserWriter implements api.current.UserWriter{
public void writeUser(api.current.User user) {
print(user.name());
}
}
// Version 2
package example.user_definitions.api.current
import example.user_definitions.api.last.User;
interface User extends api.last.User {
int age();
}
interface UserWriter extends api.last.UserWriter {
void writeUser(api.current.User user);
}
package example.user_definitions.impl.current
import example_user_definitions.api.v1.User;
import example_user_definitions.api.current.User;
import example_user_definitions.api.current.UserWriter;
class User implements api.current.User {
public String name;
public int age();
}
class UserWriter implements api.current.UserWriter {
public void writeUser(api.v1.User user) {
print(user.name());
print(user.age());
}
public void writeUser(api.current.User user) {
print(user.name());
}
}
This trick moves the awkward difference tracking code into a dedicated place that only manages the interface changes between versions and the main implementation of the code evolves as we would expect with each version containing the full implementation.
Note how somebody relying on example.user_definitions.api.v1.User will have guaranteed backward compatibility with any version of user_definitions as long as we keep adding that interface
Comparison with SemVer
Let us compare how this practice compares to the traditional semantic versioning approach from the library author’s perspective. I would like to note, that Semantic Versioning also places a burden on the library author: By increasing the minor version, the author states that backward compatibility is guaranteed. The difference is that the library author does not need to write the code to prove this compatibility.
Furthermore, SemVer is very broad as it applies to the entire interface published in the same package. Maybe someone made an incompatible change but you do not use the parts that broke. It also places the burden of assessing which range of versions is compatible with your code on the author of artifact A who has limited information about the way in which the author of D applied SemVer.
In conclusion, SemVer is approximate and broad while the approach proposed here is enforceable and fine-grained.
Other Uses Of Explicit Versions
I think that there are other techniques that the library author could use that are direct consequences of pulling the versioning information into the module system.
Once we accept the premise of separating interface (usable across versions) and implementations(tied to a specific version), we could provide a specific slow-moving package that describes the stable interface for a given major or minor version.
Another idea that could be explored is to automatically build and run a part of the test suite of the previous version against the current version. When tests are built in such a way that they use the public API, this could be used to validate backward compatibility.
Writing compatibility code for every new version sounds cumbersome. However, I think that there are tools and strategies that can be adopted to make this manageable.
Making Version Management Convenient
Let us change shift the perspective to the consumer of the library, the author of the Application package in our example above. What happens if they decide to update the version of a dependency which in turn can have updates of downstream dependencies as a consequence.
In the naive example above, the version information was baked into the module paths. This would lead to the absurd situation that the maintainer of package A would have to go through all of the places where a version has been updated. This is of course not acceptable. Luckily, I think that a relatively simple module alias extension would also solve this use case. We have two versions to worry about. One is the version of the direct dependency of a module. This can be injected from the build system where the version of the upstream dependency is defined leading to something like the following:
package example.application.current
import example.user_producer.current.UserProducer;
import example.user_consumer.current.UserConsumer;
import example.user_definitions.v1.User;
class Application {
public static void main() {
User user = UserProducer.produceUser();
UserConsumer.consumeUser(user);
}
}
This does not yet solve the entire problem: If we migrate to a new version of the UserProducer which suddenly produces a v2.User instead of a v1.User, we would still have to go into the code.
A solution would be to re-export module aliases for transitive dependencies as follows:
package example.application.current
import example.user_producer.current.UserProducer;
import example.user_consumer.current.UserConsumer;
import example.user_producer.current.dependency_exports.example.user_definitions.User as producer.User;
class Application {
public static void main() {
producer.User user = UserProducer.produceUser();
UserConsumer.consumeUser(user);
}
}
So here we know that the type of user will always be whatever the UserProducer happens to produce. The file will compile fine unless an incompatibility has been introduced.
A Word On Package Sizes
You may have noticed, that this strategy implies including multiple different versions of the same artifact. This seems like a very bad idea considering its effect on the binary size of the resulting package. In fact, the way we have defined the example packages above, the result of the build would contain the entire history of all dependencies!
A partial solution would be to split the API definitions and the implementation modules into different packages. By doing that, the result of the build would still contain the entire version history of all API definitions of all dependencies but no longer the entire history of implementations.
This is probably still not sufficient for many practical situations. I am going to handwave this problem away by observing that most of the duplicated code will not change from one version to the next. So the result of the build would contain many blocks of binary or byte code that are pretty much identical. This would thus be a good target for smart compression strategies: While you as the programmer conceptually work with v2.User and v3.User, the compiler knows that these are actually the same and would include the corresponding machine code only once in the result.
As I have not thought about this more closely, I do not want to rule out that this is more complicated than I make it seem. Let’s just say that we just saved ourselves the effort of running a SAT solver to determine a valid set of versions. I would suggest using the time we saved to instead be smart about compressing the size of the result during compilation.
Critical Security Updates
One of the big downsides I see with this scheme is that getting a certain version of a dependency out of your dependency graph now depends on maintainers of upstream components. A change slowly trickles through the graph. The traditional scheme has the property that you could inject a certain version of a downstream dependency and force your direct dependencies to use that version. That is exactly the behavior that we tried to eliminate here because of the problems it causes – but if you want to get rid of all instances of log4j 2.14 in your tree, this can be quite a useful feature.
There are several ways in which we can address this. I would suggest a mechanism in which the authors of component A can indicate that it wants to override a specific version (or set of versions). The build for package A could state: Include a V3 of a package which should then pretend to be V2.
This again introduces all the problems that we highlighted above – but it provides a mechanism that can be used in case of emergency.
Note how once all our direct dependencies have migrated away from the vulnerable version, we can automatically detect that the override is no longer necessary.
Back-Fitting This Strategy On Existing Languages
If we want to back-fit this mechanism on existing language environments we would have to deal with several challenges: I am not aware of existing module alias systems that would allow the build system to dynamically define module names based on version numbers of dependencies.
A second challenge is that we are now using interface inheritance for a use case that it was not designed for. As every new interface version of a type inherits from the previous version, these hierarchies could get quite deep. It appears that java starts to choke at depths of around 60. Practical inheritance hierarchies typically do not go deeper than around five levels. I would expect that misusing the system in this way would lead to problems in practice.
Lastly, the question is whether the version management strategy could be back-fitted easily to packages that have not followed this versioning strategy in the past. I think it would be possible to write wrapper packages to existing libraries that introduce the versioning interfaces but delegate the implementation to the un-versioned library. This would be an enormous amount of work. It feels a bit comparable to the creation of type packages to use existing JS modules in TypeScript.
Conclusion
There are other concerns that I did not address such as the fact that not all properties that constitute the interface of a package are captured in the types exported by the package. My main concerns were whether the practice of juggling several versions of the same package can be made practical and whether this could be back-fitted into an existing ecosystem.
My conclusion on both accounts is that I am still not convinced.
However, if this could be implemented, I think it might lead to more elegant version management in which package versions become first-class citizens and in which we can leverage the type system to make statements about compatibility between versions.

Leave a comment