If we had to write a list of typical skills we expect of Software Engineers, “writing clean code” would probably be on it. However, the trouble with clean code is that it is hardly an objective measure. I don’t think I’ve ever worked in a team where everyone had the same understanding of what it means for code to be “clean”. I cannot even agree with my past self on this!
I want to have another stab at this topic, trying to abstract away from simple best practices towards some more underlying principles, guided by the question of why we want code to be “clean” in the first place.

I’ve proposed earlier that units of code should probably provide a simple response to the question “what does this thing do?”. I have also argued that a way of measuring code quality might be to have a team find and resolve a bug in a foreign codebase.
Both of these considerations grew out of the same underlying motivation: The biggest difference between low-quality code and high-quality (clean) code is in the future business risk associated with this code: How easy is it to make changes later? How quickly can you find the problem that brought down production? How difficult is it to onboard new team members? Each of these has a real monetary long-term value.
Furthermore, these activities hinge on the ability of an engineer (your future self or someone else) to quickly understand what is going on in your code.
Trying to find a bit of a compass to get some sense of what makes code hard or easy to understand, I think we should have another listen to Rich Hickey’s classic talk “Simple Made Easy”. If you haven’t watched it yet, it’s worth it:
The important realization here is that simple and easy do not mean the same thing. Simplicity is something that we can assess relatively objectively: Between two possible solutions, we can identify the one which has fewer entangled elements. To see what is going on at a certain place of the code, you need to keep track of fewer moving parts.
Easy, on the other hand, is related to familiarity and therefore by its very definition subjective: If you have worked your entire life in Java, you will find it easier to read Java code than to read code written in Lisp.
I would suggest that if we want to come up with any measure for clean code, both of these dimensions are potentially valuable and should be evaluated separately: If you take the average time it would take a skilled person unfamiliar with the code to solve a critical bug as a proxy for quality, you can see how both simplicity and familiarity are factors that should improve this metric:
- By making the code simpler, there are fewer elements to juggle, there are fewer factors to consider when reproducing the issue, and fewer chains to trace back to find the origin of the problem.
- By making the code more familiar, the person executing the emergency operation will have a better mental model of the inner workings of the code and they will be quicker identifying the critical places.
The former can be achieved by thinking about components and interactions: Can the use of shared mutable state be avoided? Can interfaces between components be designed in a way that timing is not an issue? Familiarity, on the other hand, can be achieved by following patterns and best practices that are considered industry standards.
If we think about the situation as a matrix like below, two quadrants are not very interesting: Patterns that are both unfamiliar and complicated are probably to be avoided. Patterns that are simple and easy are unambiguously good. What about the two quadrants where the two are in conflict?
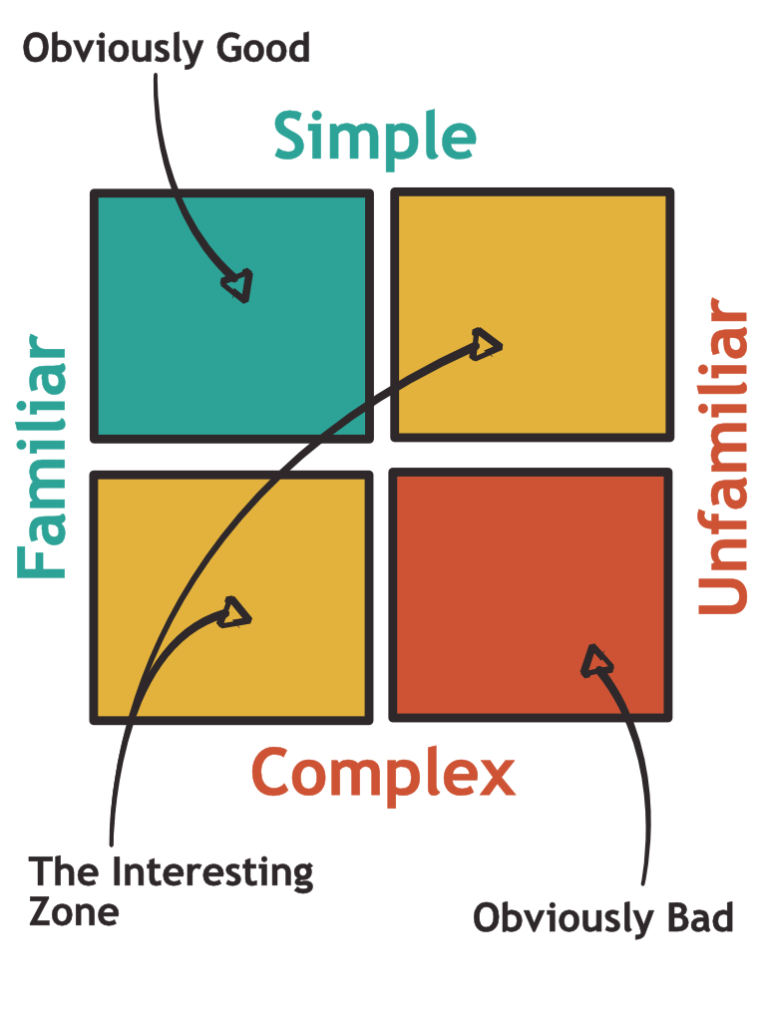
It is not obvious to me if in the short term it is preferable to have unintuitive simple code or intuitive but complicated code. It is, however, clear that simplicity is a durable quality that exists even if the context, the people, and the fashion change. Code that is considered easy today may, however, no longer be considered easy in ten years.
Importantly, habits can be changed. Practices that are simple and unintuitive can be brought into the upper left quadrant by changing people’s expectations. Such a culture change certainly takes effort and time. A complex solution, on the other hand, can never be turned into a simple solution by a cultural change. Consider the following description of how Google introduced std::unique_ptr into their C++ style guide:
When C++11 introduced std::unique_ptr, a smart pointer type that expresses exclusive ownership of a dynamically allocated object and deletes the object when the unique_ptr goes out of scope, our style guide initially disallowed usage. The behavior of the unique_ptr was unfamiliar to most engineers, and the related move semantics that the language introduced were very new and, to most engineers, very confusing. Preventing the introduction of std::unique_ptr in the codebase seemed the safer choice. We updated our tooling to catch references to the disallowed type and kept our existing guidance recommending other types of existing smart pointers.
Time passed. Engineers had a chance to adjust to the implications of move semantics and we became increasingly convinced that using std::unique_ptr was directly in line with the goals of our style guidance. The information regarding object ownership that a std::unique_ptr facilitates at a function call site makes it far easier for a reader to understand that code. The added complexity of introducing this new type, and the novel move semantics that come with it, was still a strong concern, but the significant improvement in the long-term overall state of the codebase made the adoption of std::unique_ptr a worthwhile trade-off.
(Software Engineering At Google)
Note how, under appropriate circumstances, using a unique pointer is simpler than using a traditional pointer as there are fewer different states that the program can be in. You do not need to consider the possibility that someone else holds a reference to the same object.
As the concept was at first unfamiliar, this was a top-right quadrant situation. However, over time the attitude changed as more people became familiar with the concept which moved this same pattern closer to the top-left of the matrix.
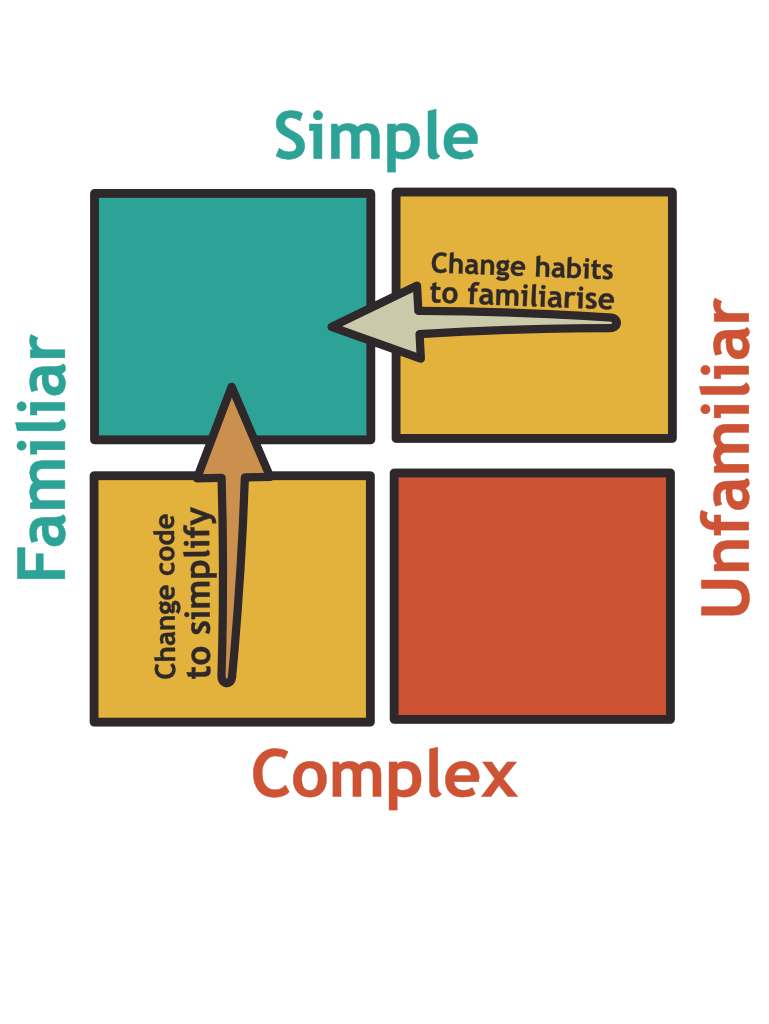
This leads to the following conclusion: Firstly, as both dimensions have value, it is a good short-term strategy to use the simplest possible code that people are familiar with (move up on the left side).
Secondly, moving left from the top-right corner requires a change of habits and is thus a culture change. This is a long campaign and will require a lot of work.
Lastly, we can never objectively speak of clean code without consideration of the context. The goalpost is constantly moving. We can, however, use simplicity as a criterion to guide our long-term efforts as it is the closest to an objective standard that we can get.

Leave a comment