Like with any kind of data, to fully understand the map data design space, we need to understand both the way it is used from a consumer perspective and the way that it is produced. Understanding the different requirements of producers and consumers leads to a better understanding of the solution space and the design trade-offs involved in creating a map product.
This article is part of a series around the specific challenges of working with map data. Part one of the series can be found here.

Consuming Map Data
In an earlier article, I considered that one of the features that differentiate a map from a simple collection of geospatial datapoints is the way that objects form relations. This article raised one of the criteria that make a map easier to use for a consumer: Ideally, as we saw in the previous article, map geometries form a planar graph and semantic meaning is defined in a layer on top. That way, a consumer of this data can run queries on the topological properties of the map without having to resort to numerical operations.
Let us consider an example: Imagine a use case in which you would like to know if a route crosses an international border. Given only a linestring describing the route and a list of polygons describing country shapes, the best you could do is to run a numerical algorithm to determine if the two geometries intersect. If, however, it was known that the data forms a planar graph, the only way that a route could traverse an international border would be through a node that is both part of the route and part of the line that marks the border geometry. While the numerical operation can suffer from numerical instabilities, the latter procedure is deterministic and will always produce the desired result.
A second important observation is that map data – like any other form of data – needs to be read and interpreted according to a schema. Therefore, all the typical challenges of data formats apply:
- How does the consumer know how to interpret the data? Schema documentation and metadata are often required to read the data correctly.
- How can the consumer deal with changes in the data specification? How is schema evolution performed? Important questions revolve around compatability: Will a new version of the map still work with a previous version of the software consuming the data?
The schema of the data also typically provides invariants that a consumer would require to be true: A polygon should always be a closed shape. IDs should always be unique. A capital city should always have a name. An object must never reference an object that has been deleted. The more assumptions a consumer can make about the data, the easier the implementation of a system consuming this data as fewer edge cases need to be accounted for.
The last consideration that I would like to point out is that a consumer also needs to deal with changes to the data itself. One important question to ask is: Can a consumer identify that two objects from two different versions of the map reference the same real-world entity? Being able to trace this lineage makes it easier to mix data that the consumer stores on their side with data they receive through the map.
Consider a use case in which you allow your users to store routes in your system to be consulted later. An easy implementation would be to store a route as a sequence of road element IDs. However, consider what would happen if you update the map data and one of the road elements is split in half – resulting in at least one road element with a new ID. The sequence of IDs stored in your database now no longer represents the same route in the new data.
An idea could be to provide stable identifiers that reference a logical entity in the map and to make sure that all objects that represent this logical entity in future map versions receive this identifier. That would lead to two different ID conventions: One technical object ID which is guaranteed to be unique and one logical ID which tracks historical lineage.
Implementing such a system would face a lot of practical challenges and grey areas. Open Street Map, for example, allows amenities to be tagged on a point, resembling a typical point of interest (POI) dataset. The same tags could also be added to a building in which the amenity is hushed. What happens if the data is updated in such a way that the amenity tags on the building move to a node or vice versa? Would this trigger the stable object lineage requirement?
Furthermore, what happens if an object changes in reality? From what point onwards would we require the object lineage to change? Do we change the lineage when the name of an amenity changes or when its owner changes for example?
Runtime Formats
An import side note when considering the consumer perspective on map data is the difference between exchange formats and runtime formats.
Typically, the format that you receive a map in will be normalized as the map maker does not yet know your use case. A normalized format makes it easier to give guarantees as described above. However, such a format is not necessarily appropriate for your access pattern. Therefore, using map data usually involves transforming the normalized map into a de-normalized runtime format. This transformation may also produce derived data like indices or other lookup structures. The goal is always to optimize the data for the queries that the specific use case requires.
The requirements from an on-board routing engine are very different from the requirements of an online geocoding service and it would not be reasonable to expect one data format to support both use cases equally well.
A conclusion for the map maker is the following: The format in which map data is exchanged does not necessarily need to be optimized for particular lookups. The primary use case that this map data needs to be optimized for is transformation into a different format, which in turn is optimized for a specific use case. Put in other words: The consumer of map data is almost always another transformation process.
Producing Map Data
Production processes have the opposite challenges when it comes to many of the points noted above. Let us first of all consider where map data comes from: Usually, maps are a merge of a variety of data sources. OpenStreetMap for example heavily relies on people manually editing the map based on satellite images and GPS traces. However, there were several large scale ingestions of external data sets: The US road network data for example was kickstarted by an import of the public domain TIGER data.
Combining different data sets necessarily means collecting objects that follow different conventions and connecting points that were not designed to be connected. If the producer of the map wants to provide data that is convenient for the consumer to use, the producer will be faced with all the problems that the consumer wants to avoid: Making non-planar data planar through numerical operations, unifying data sets that follow different conventions under a common schema and avoiding duplicates.
When it comes to schema evolution, production processes are faced with the flipside of the backwards compatibility issue that the consumer faces: How can a producer deal with changes in the data specification? Is old data left in the database still compatible with newer versions of the producer software?
Tensions Between Producer Focus and Consumer Focus
The main point I want to make in this article is that there is a tension between the consumer perspective and the producer perspective: Defining a data format that is convenient for a consumer can make things harder for the producer and vice versa.
To see this difference in perspectives, let us first recall what it means to be backwards- or forwards compatible in data formats:
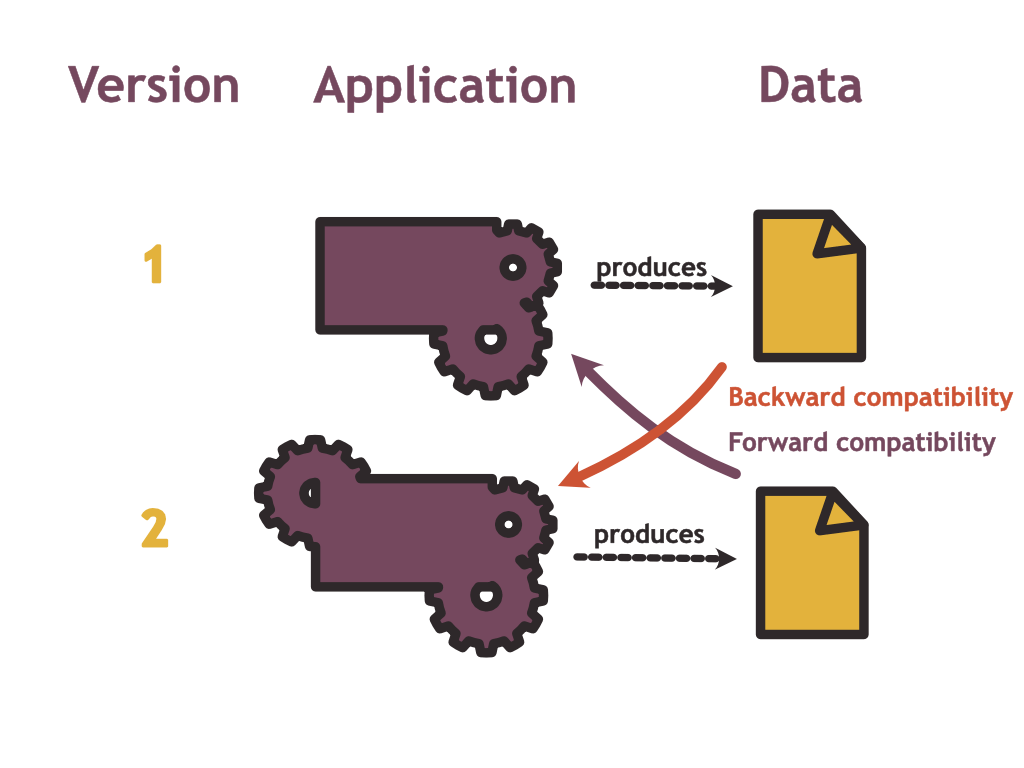
To be backwards compatible, the new version of your application which uses a new data schema should still be able to read data written by a previous version. To be forwards compatible, an old version of the application should still be able to read data written with a new schema.
Now let us consider what this looks like for the producers and consumers of map data:
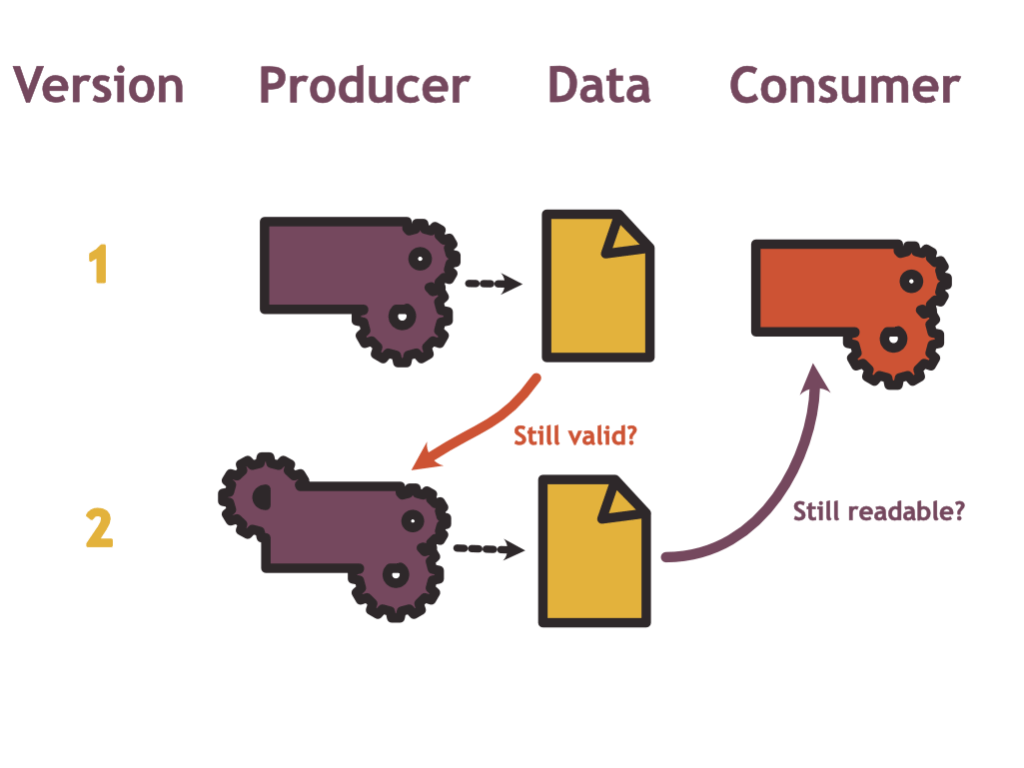
From the producer’s perspective, the main challenge with regard to schema migration is one of backwards compatibility: Is the data that I have produced in the past still compliant with the new model?
From the consumer’s perspective on the other hand, the problem looks more like a forwards compatibility question: To minimise effort for the consumer, the same old processing pipeline still needs to be able to read data produced with the new schema.
How are these conflicting? Consider the example of adding a new surface material attribute to road element objects. The easiest course of action from the producer’s perspective is to make this attribute optional and thereby making the schema change backwards compatible. The producer could start populating this data in those areas where data sources are available and not populate them where sources are currently lacking.
From the consumer’s perspective, adding a new field is (under some assumptions) a forwards compatible change. It would be even better if this field wasn’t optional as the consumer could then rely on this data being present and reduce the number of cases to handle.
On the flip side, making a field optional in the new version of the map model is a backwards compatible change from the producer’s perspective. This can be an important change as new data sources might not expose the required information. For the consumer, however, this is not a forwards compatibility change as the software could rely on the assumptions that this data is always present.
Next to the question of compatibility, consider the example of building entrances: Do you want the producer of the map to link buildings to the road network at the appropriate locations as I suggested earlier, or do you want the consumer to guess this association based on geographical proximity?
If routing to a building is a use case, this association needs to happen somewhere, and making life easier for the consumer requires more work for the producer and vice versa.
What Is Quality?
Before looking at the example of OpenStreetMap, I would like to address the word “quality” in this context. We could see the quality of map data as the accuracy and the completeness with which it represents the real world. However, in practice, it is – as always – a bit more complicated.
There are several categories of quality issues a map can face:
- Completeness problems: A road exists in the real world but it is not part of the map dataset.
- Format problems: A road exists in the real world and it is part of the map dataset – however it’s data is not according to schema making it hard for consumers to process it.
- Accuracy problems: A road exists in the real world and there is a corresponding object in the map data, however the geometry deviates from the real-world geometry and the speed limit attribute is set incorrectly.
- Freshness problems: There exists a road in the map data, however the road in the real world has been severely damaged and is closed for all traffic.
Without considering the use case, it is hard to state which of these quality problems are more severe: Is it better to not have an object in the map for a given real-world entity or to have something that is inaccurate? A routing engine sending a driver over a non-existing bridge is likely unacceptable. If I’m looking for an Italian restaurant in my area, I might accept calling a couple of unavailable numbers if in exchange I can be confident that all existing restaurants are in the dataset.
How does this discussion relate to the producer-consumer tradeoff? I would argue that the decision whether to put the focus on the consumer or on the producer depends in part on which of the above quality aspects you value most.
Making a map more convenient to edit could lower the bar for producers and reduce the number of freshness and completeness problems. However, you might have problems with format and accuracy: If your schema requires that each road element needs to have a speed limit, a producer that only knows about the existence of the road but not about the speed limit will not be able to add it to the data until that information is available. If you are flexible in this requirement, the road can be added but the consumer can not rely on speed limit information being available.
How Open Street Map Handles This Trade-Off
The above elaboration leads to what I think is an important difference between the Open Street Map project and commercial maps that are available on the market.
The Open Street Map is maintained by an army of volunteers (even though more and more contributions are coming from corporate entities). It only works because its barrier to entry is low. For this very obvious reason, it is optimized for convenient editing.
Commercial maps on the other hand often have a much stronger focus on convenient consumption as they try to cater as much as possible to their paying customers.
To see how Open Street Map favors production over consumption, consider the way its schema is defined: First of all, the only thing that is cast in stone are the three base primitives nodes, ways and relations. All the meaning assigned to these primitives is conveyed through tags. These tags, however, are often informal and their meaning is defined by the current state of the OSM wiki.
Some tags are very well established: building=yes designates a building of unknown type, boundary=administrative is assigned to an administrative area such as a country or a province.
However, imagine you wanted to tag a road with the maximum speed that it can be driven on in practice (which can be lower than the legal speed limit). You could use the maxspeed:practical tag. A proposal to make this tag official was rejected. Nevertheless, at the time of writing, there are globally 26377 ways using this tag. Whether or not this tag can reliably be used for use cases such as ETA estimation solely relies on the traction it generates in the community, whether volunteers will start tracking and policing this information. It may, however, very well happen that a different convention will obtain swarm consensus at some point in the future.
To some degree, the most popular software applications consuming OpenStreetMap data have a large impact on what is widely accepted as specification and what is not: If a tag is taken into account by the OpenStreetMap Carto stylesheet which defines the default look of the rendered OSM map, more editors will be motivated maintaining and correcting it.
We have seen, the standard OSM map data model is optimized for editing. Like other exchange formats, this data model is not optimized for particular use cases such as search, routing or rendering. To support this functionality, the public OSM stack relies on derived data.
Conclusion
Producing and consuming map data are two poles that influence each other. OpenStreetMap being a radically pragmatic project is heavily optimised towards convenient production.

{kind=link}